The AI Challenge: Who Will Pay for Content
During a groundbreaking move, Cloudflare announced a new business model in closed beta called Pay Per Crawl, allowing website owners to charge AI crawlers for every request to access their content. Has the mechanism finally arrived that will let creators earn from their work in a world where many searches now start with an AI answer?
The content world is under siege. AI crawlers read sites and summarize the information, but few users click through to the original links. The result: a sharp drop in traffic to the sites, damage to digital advertising, and a real threat to the economic foundation of content creators. Today, the first technological answer has arrived.
Cloudflare CEO Matthew Prince (Cloudflare CEO) told Axios [2]:
“Artificial intelligence is killing the business model of the internet. People trust AI more than ever, so they don’t bother to read the original content.”
On June 1st, 2025, Cloudflare unveiled a revolutionary fix with the launch of Pay per Crawl. For the first time, website owners can charge AI crawlers (from OpenAI, Anthropic, and others) for access to their content. The mechanism relies on the little-used HTTP 402 Payment Required status code—an architectural add-on to the existing web.
The Unwritten Pact With Creators Is Cracking
Nearly 30 years ago, two Stanford students created Backrub. It became Google and laid the foundations of the internet’s business model.
The informal deal between Google and site owners was simple:
Let us copy your content for search results; we’ll send you traffic so you can monetize through ads, subscriptions, or simply the joy of being read.
Google built the infrastructure: Search generated traffic, DoubleClick + AdSense generated revenue, and Urchin (a web analytics company Google acquired in 2005 that became the foundation of Google Analytics) became Google Analytics so everything could be measured.
For almost three decades, that bargain kept the web alive.
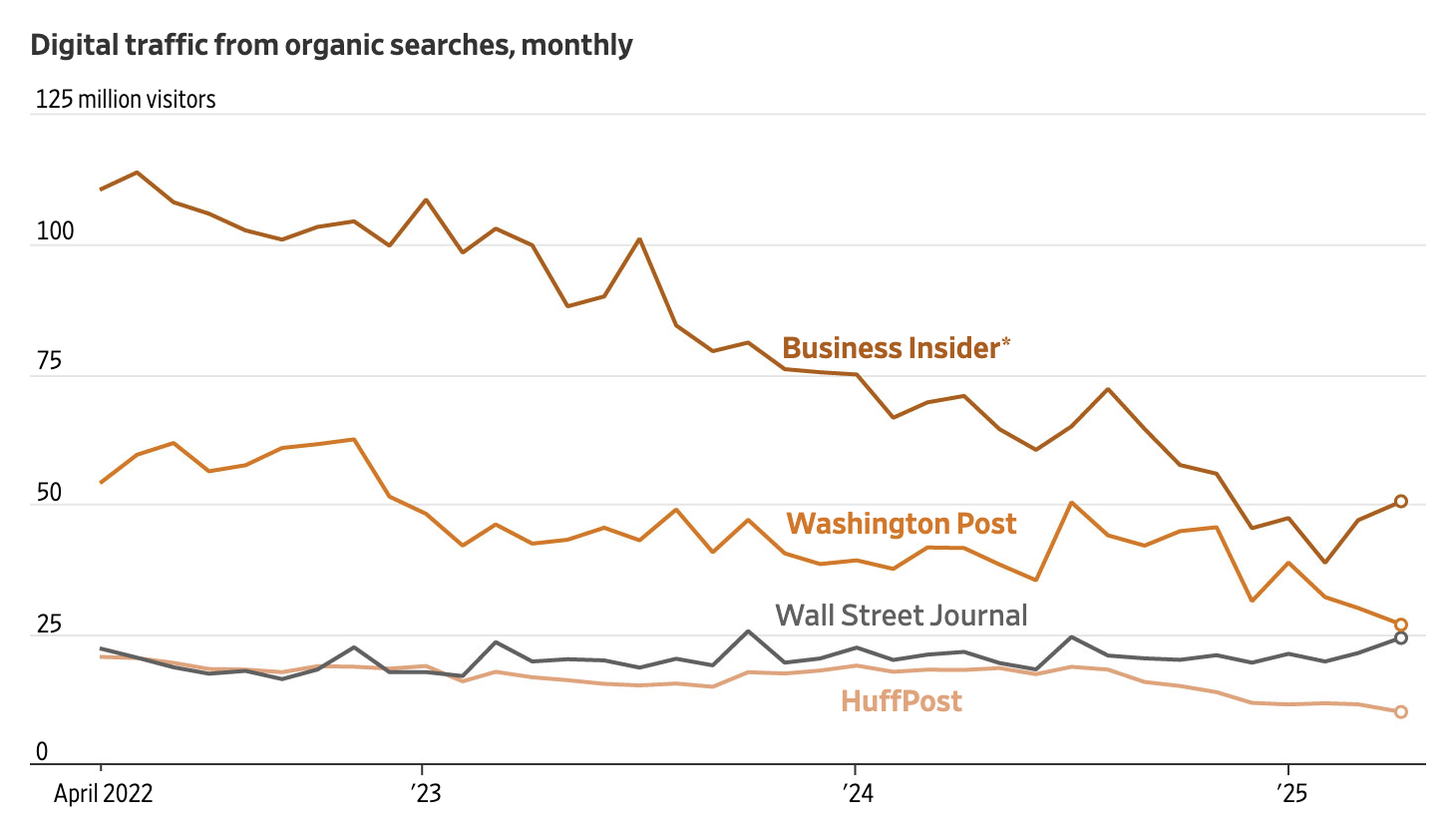
But the deal is eroding. Google queries are declining for the first time ever. What is replacing them? AI.
Matthew Prince’s numbers [2]:
- 10 years ago — Google crawled 2 pages per 1 visitor it sent.
- 6 months ago — Google 6:1 • OpenAI 250:1 • Anthropic 6,000:1
- Today — Google 18:1 • OpenAI 1,500:1 • Anthropic 60,000:1
The trend is clear: Google’s mutual deal is crumbling and creators are left out.
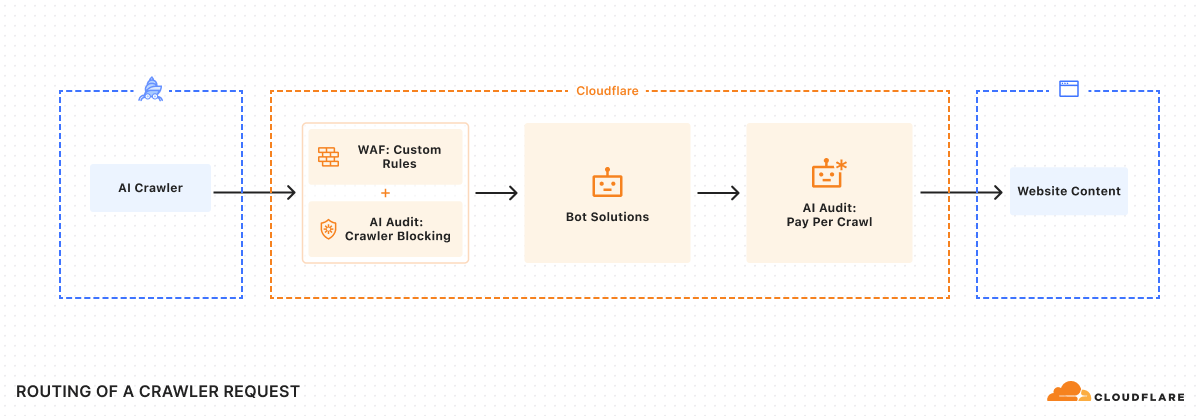
How Pay Per Crawl Works
Instead of blocking all crawlers or giving them free access, site owners now have a third option: charge.
For each AI-crawler request, the server can return HTTP 402 with a price. If the crawler agrees, it resends the request with payment intent and receives the content (HTTP 200). If not, access is denied.
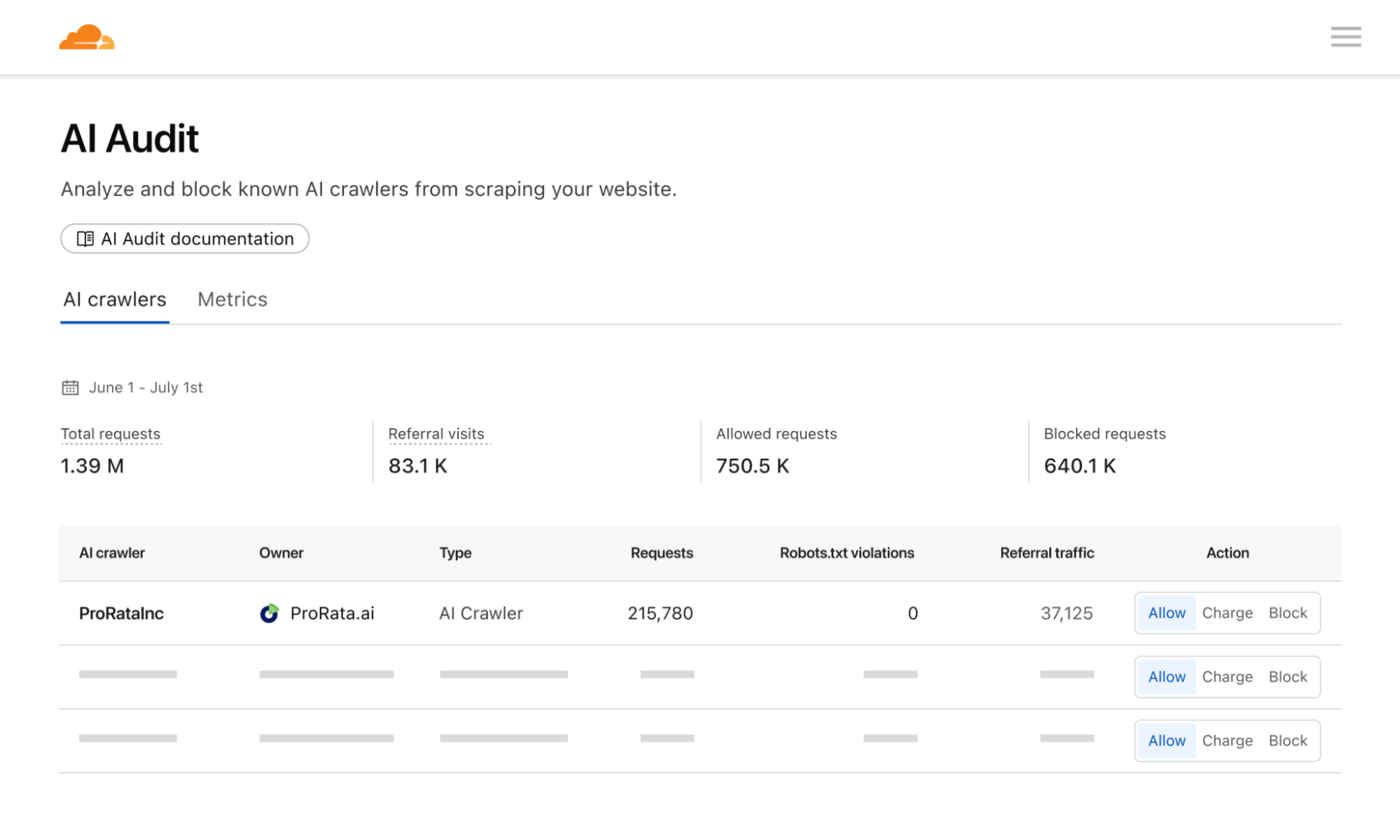
In Cloudflare’s dashboard, publishers can set for each crawler:
- Allow free access (200)
- Charge per request (402 + price)
- Block but signal payment is possible (403)